
上海临床研究中心聚焦临床医学与人工智能的深度融合,致力于推动AI技术在真实医疗场景中的可信应用与转化落地。近期,中心姜畅、刘心雨、周文哲、李寒露医师与上海科技大学信息科学与技术学院李权课题组(交互智能与可视分析实验室ViSeer LAB)紧密合作,围绕医生对AI辅助诊断的信任评估开展研究,相关成果被人机交互领域最具影响力的国际会议ACM CHI 2026录用。
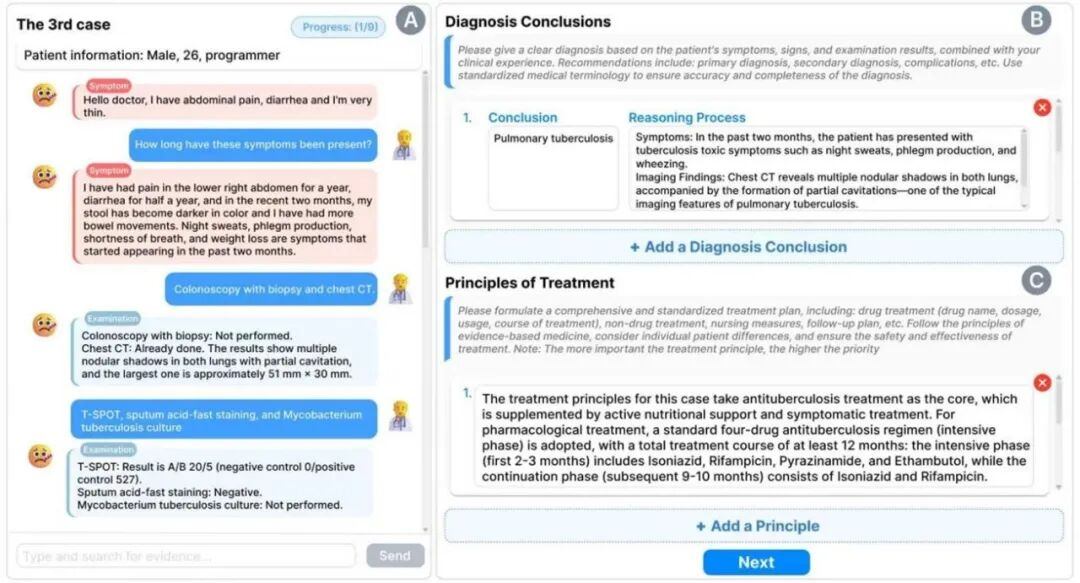
图1. 使用系统与大模型模拟的病人问诊,收集案例分析的诊断数据。
在医疗人工智能快速发展的背景下,大语言模型展现出辅助疾病诊断的巨大潜力。然而,其融入临床实践的核心障碍——医生是否真正信任AI的判断——仍未得到充分理解。针对这一关键问题,上海临床研究中心姜畅、刘心雨、周文哲、李寒露医师与李权课题组联合开展了深入研究。
该研究创新性地提出一套量化评估框架,将医生对AI的主观感知转化为可比较的“感知能力得分”,为构建更安全、可信的AI辅助诊断系统提供了关键依据。区别于传统依赖标准化医学题库准确率的评估方式,本研究紧密贴合真实临床决策的动态性与复杂性,完整涵盖从病史询问、证据整合到鉴别诊断与治疗规划的全流程。
研究采用两阶段交互式实验设计。首先,团队构建了9个涵盖不同专科的真实临床病例,由不同资历的医生与包括GPT、Gemini在内的6个主流大语言模型分别进行独立诊断分析。在此基础上,研究团队招募37名医生作为评估者,从诊断询问的逻辑连贯性、诊断结论的准确性与全面性、推理过程的严谨性、治疗原则的合理性与全面性、以及临床可接受性共7个核心维度,对所有分析报告进行盲评与排序。通过采用Bradley-Terry排序回归模型及累积链接混合模型等统计方法,研究者成功将多维评分综合为统一的“感知能力得分”,从而实现了对AI临床推理能力的量化度量。
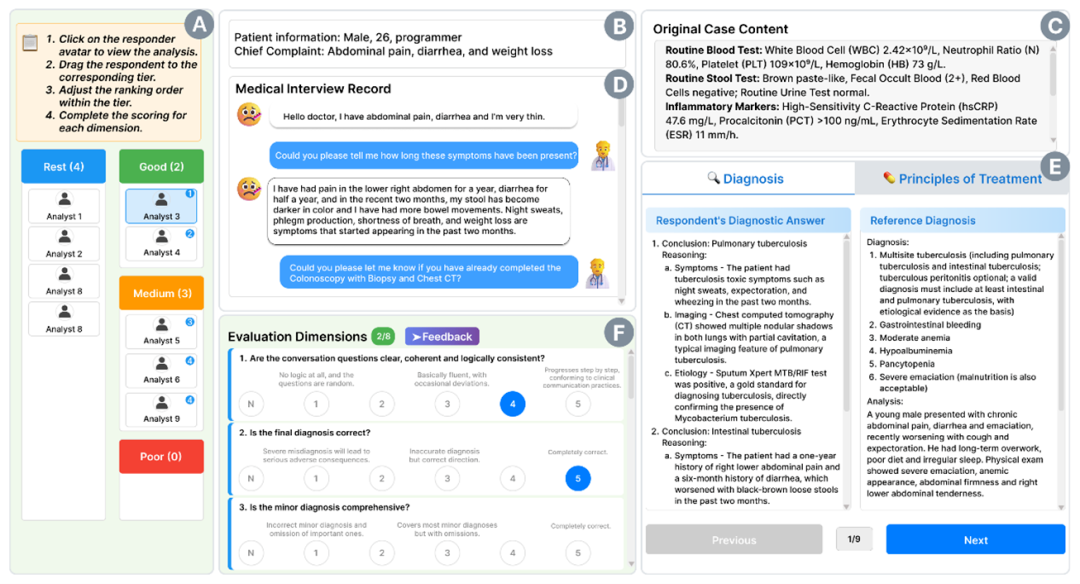
图2.使用系统对不同的案例分析进行排序和具体维度的打分,收集用户感知的临床推理数据。
研究发现了几项关键洞察。其一,AI在标准化基准测试上的表现与医生的感知能力虽呈正相关,但达到一定阈值后呈现边际效益递减,表明仅追求基准高分不足以建立充分信任。其二,“临床可接受性”——即诊断与治疗方案在实际场景中的可行性、可操作性及风险意识——在所有维度中对医生整体评价的影响权重最高,这意味着即便诊断结论正确,若推理过程脱离临床实际,也难以获得医生认可。其三,传统评估体系过度聚焦“诊断结论准确性”,相对忽视了医生同样重视的“诊断询问逻辑性”“治疗原则全面性”等维度,暴露出与真实临床需求的脱节。其四,表现最佳的大语言模型在整体评估中稳定优于多数非专科医生,并与专科高年资医师表现相当,证实了其在辅助复杂临床推理方面的切实潜力。
该研究以“Do I Trust the AI?” Towards Trustworthy AI-Assisted Diagnosis: Understanding User Perception in LLM-Supported Reasoning”为题发表于ACM CHI 2026。ACM CHI 2026将于2026年4月13日至17日在西班牙巴塞罗那召开。
文章链接: